Latencias — más allá de Madrid — a la región de Google Cloud Platform en España
En este artículo de blog se compararán las latencias entre las regiones de Madrid y Bélgica desde toda la geografía nacional española usando RIPE Atlas


Como ya he comentado anteriormente en el siguiente artículo de blog, se ha lanzado la nueva región de Google Cloud Platform (GCP) en Madrid.

Objetivo y metodología
Las ventajas de esta nueva región son múltiples, empezando por el descenso de latencia a nivel general de unos 20ms para Madrid como se puede ver aquí. Pero, aunque haya quien piense de forma distinta, ¡hay más allá de Madrid! En este artículo de blog veremos las latencias reales desde 165 puntos de nuestra geografía.
Además de medir las latencias desde estos 165 puntos hasta la región de Madrid, se repetirán las mismas pruebas contra la región de Bélgica. De esta forma conseguiremos una comparativa real de las ganancias en latencia con la apertura de la nueva región.
Las mediciones se han realizado contra dos máquinas virtuales, una en cada región (Bélgica y Madrid):

¿Estaba en lo cierto Javier Martínez cuando aseguraba latencias de 1ms para la Comunidad de Madrid en la sesión de presentación celebrada el pasado 25 de mayo? Adelanto: ¡Sí, estaba en lo cierto! ?

Pero, ¿cómo se va a realizar las mediciones desde más de 150 puntos de la geografía nacional? ¡Eso son muchos sitios distintos! Con una herramienta fantástica: RIPE Atlas.
¿Qué es RIPE Atlas?
RIPE Atlas es una de las plataformas de medición de parámetros de red en Internet de mayor despliegue a nivel mundial. Pone a disposición de sus miembros recursos que permiten realizar mediciones de redes. RIPE NCC es el organismo encargado de llevar adelante este proyecto.
La red global de sondas RIPE Atlas realiza mediciones activas acerca de la conectividad y capacidad de alcance de Internet. Esta red facilita una comprensión sin precedentes acerca del estado de Internet en tiempo real para toda la comunidad de Internet: cualquiera puede acceder a los mapas, estadísticas y resultados de las mediciones de RIPE Atlas.
RIPE Atlas es usada por miles de personas, investigadoras/es y administradores de red para, por ejemplo :
- Monitorizar continuamente la capacidad de alcance de la red desde miles de puntos de observación alrededor del mundo.
- Investigar y detectar problemas de red con controles de conectividad rápidos y flexibles.
- Crear alarmas usando los comprobadores de estado de RIPE Atlas, que pueden integrarse con sus propias herramientas de monitorización.
- Medir la capacidad de respuesta de su infraestructura DNS o la de los servidores raíz.
- Probar la conectividad IPv6.
Como ejemplos, podemos destacar el estudio que hizo la fundación Wikimedia (que gestiona, entre otros proyectos, Wikipedia) para saber dónde posicionar puntos de presencia (PoPs) para su Red de Distribución de Contenido (CDN) internacional y desde cuál servir a los diferentes usuarios.
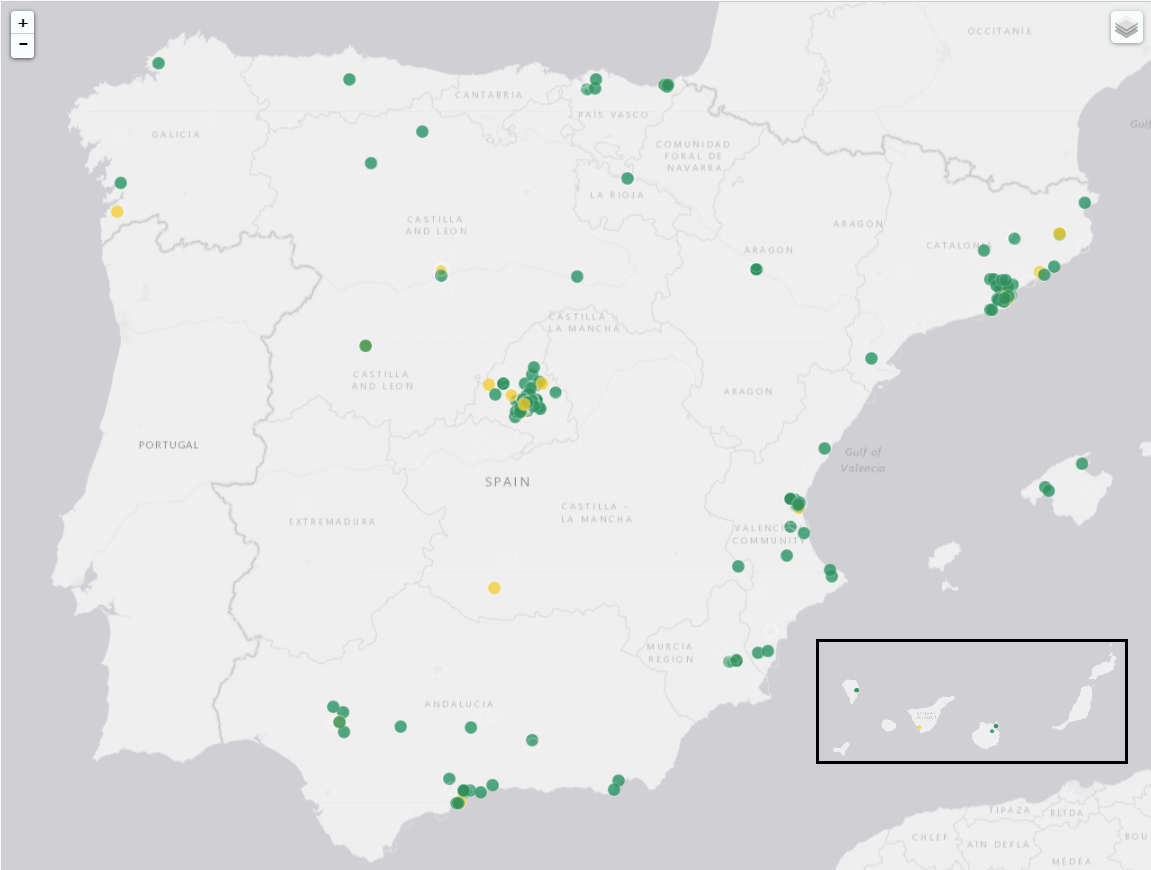
En la siguiente imagen podemos ver la cantidad de dispositivos en España conectados a la red de RIPE (en adelante, probes) desde los que podemos lanzar mediciones. También puedes consultar la información más actualizada en este enlace.
Resultados
En las siguientes imágenes veremos las latencias sobre un mapa de nuestra geografía. En las capturas se omiten los datos de las Islas Canarias, pero se pueden consultar en los enlaces correspondientes.
También se ha generado un Dashboard de Google Data Studio para facilitar la comparativa. (Lo puedes encontrar a continuación en este artículo).
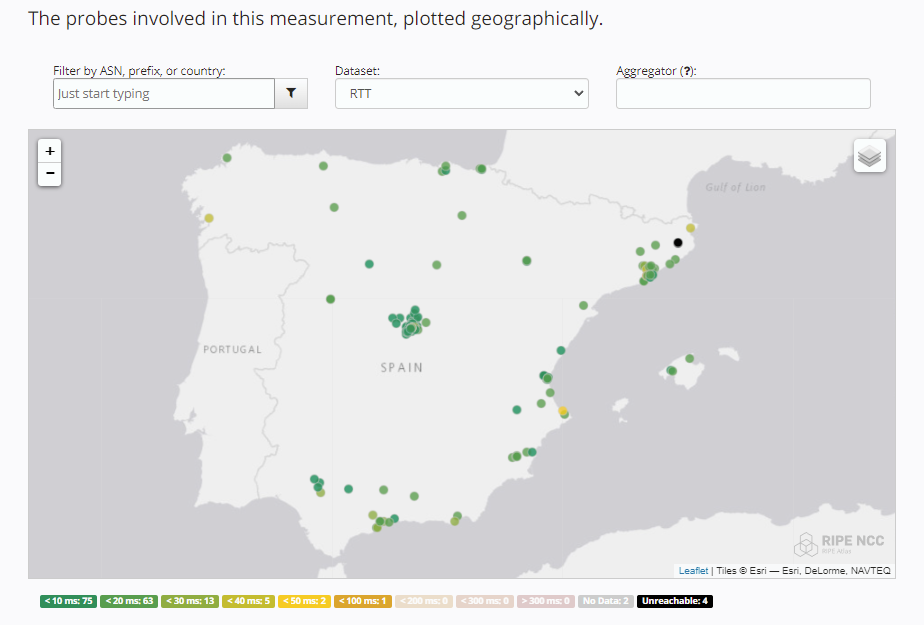
Latencias a la región de Madrid
Puedes acceder a los detalles desde este enlace.
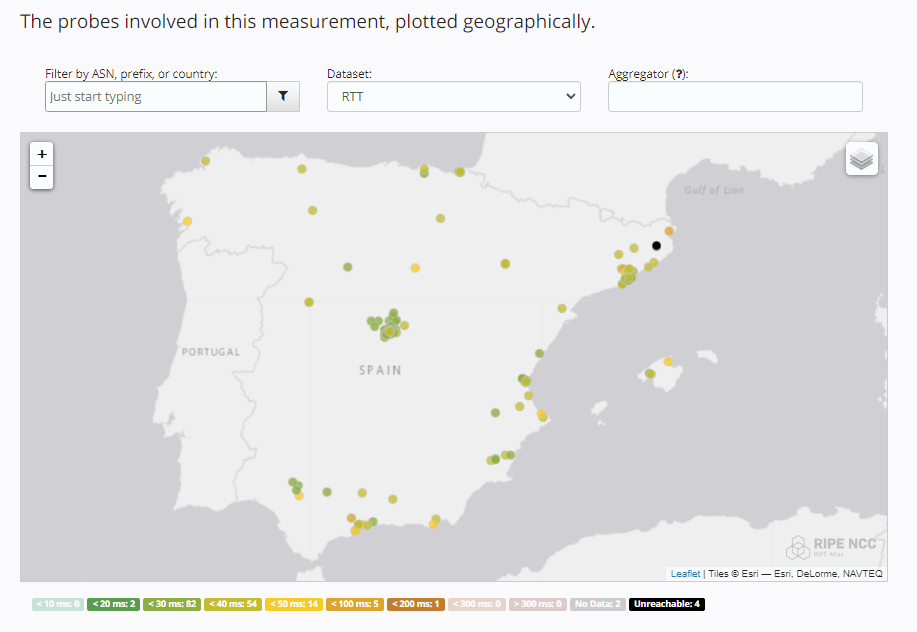
Latencias a la región de Bélgica
Puedes acceder a los detalles desde este enlace.
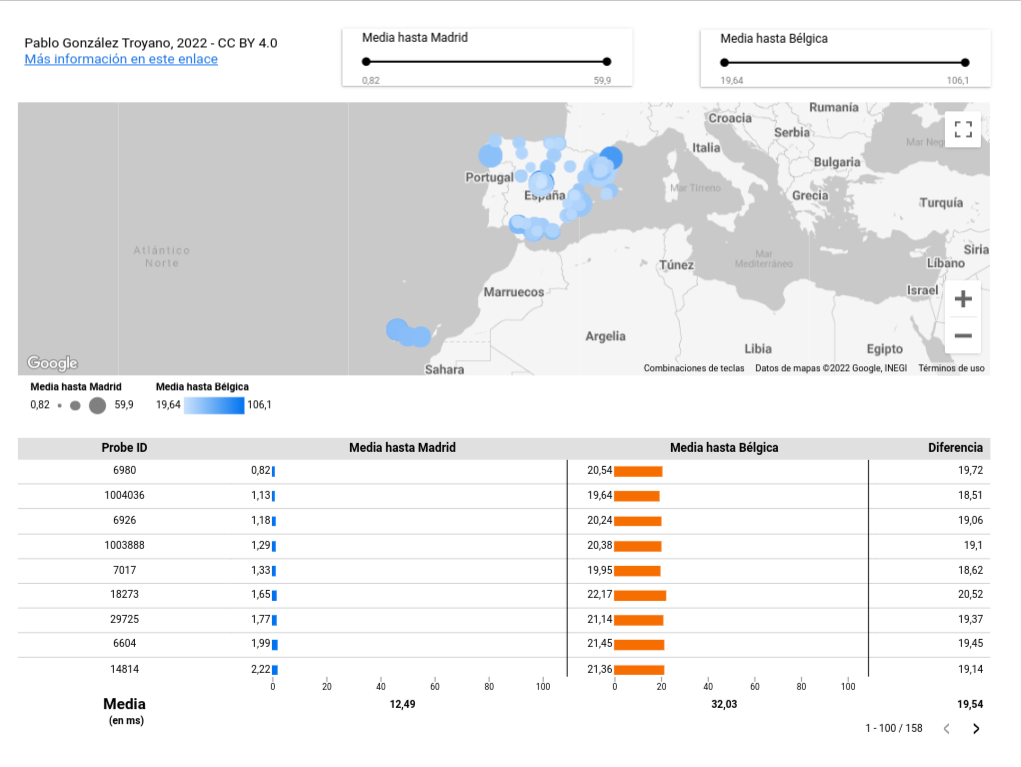
Informe de resumen en Google Data Studio
Haciendo clic en la imagen a continuación podrás acceder a un informe en Google Data Studio en el que podrás acceder a todos los datos. Está dividido en dos secciones: un mapa interactivo en la parte superior y una tabla en la parte inferior.
Moviéndote por el mapa verás diversos puntos. El tamaño indica la latencia hasta Madrid; a menor tamaño, menor latencia. El color indica la latencia hasta la región de Bélgica; cuanto más claro es el color, menor latencia. Si haces clic sobre un punto verás el Identificador de la Probe sobre la que se ha lanzado la medición, así como las latencias a ambas regiones.
En la tabla inferior puedes ordenar los valores de las columnas. También existe una columna en la que se puede consultar la diferencia de latencias entre ambas zonas. En la parte inferior de la tabla se encuentra la media de todos los valores. Tal y como se puede ver, la diferencia media de latencia está en 19,54 ms.
Para “frikis”: cocinado de datos para el informe de GDS
En esta sección explicaré cómo he tratado los datos para prepararlos y subirlos a Google Big Query (también llamado, cocinarlos).
En ningún momento se han modificado los valores, eso vaya por delante. Pero, para general el mapa, por ejemplo, debemos facilitar la información de una forma definida. Además, desde los enlaces de descarga de los resultados no se proveen las coordenadas de las Probes. Por este motivo, hay que conseguirlo y luego unirlo todo.
Descarga de datos de las pruebas
Descargamos los datos (formato json-nd) desde los siguientes enlaces
- https://atlas.ripe.net/measurements/41688525/#download (Para ES)
- https://atlas.ripe.net/measurements/41688561/#download (Para BE)
El resultado serán dos archivos JSON con el siguiente formato:
{"fw":5020,"mver":"2.2.1","lts":54,"dst_name":"34.175.157.154","af":4,"dst_addr":"34.175.157.154","src_addr":"192.168.10.6","proto":"ICMP","ttl":57,"size":48,"result":[{"rtt":13.795059},{"rtt":103.823696},{"rtt":62.095018}],"dup":0,"rcvd":3,"sent":3,"min":13.795059,"max":103.823696,"avg":59.904591,"msm_id":41688525,"prb_id":1000650,"timestamp":1654958489,"msm_name":"Ping","from":"79.156.126.125","type":"ping","group_id":41688525,"step":null,"stored_timestamp":1654958500}
{"fw":5020,"mver":"2.2.1","lts":50,"dst_name":"34.175.157.154","af":4,"dst_addr":"34.175.157.154","src_addr":"172.18.1.17","proto":"ICMP","ttl":57,"size":48,"result":[{"rtt":5.551287},{"rtt":4.829184},{"rtt":4.798678}],"dup":0,"rcvd":3,"sent":3,"min":4.798678,"max":5.551287,"avg":5.0597163333,"msm_id":41688525,"prb_id":1000961,"timestamp":1654958489,"msm_name":"Ping","from":"83.38.84.45","type":"ping","group_id":41688525,"step":null,"stored_timestamp":1654958499}Lo subiremos a GCS, bien mediante la interfaz web, usando gsutil o cualquier otra opción disponible.
Conjuntos de datos - measurements
Creamos el conjunto de datos altas-latency-mad-gcp-zone. En este momento crearemos dos tablas:
- belgium
- spain
Evidentemente, cada una tendrá los resultados de cada correspondiente measurement. En la imagen a continuación podemos ver el ejemplo de la tabla belgium.
Ejemplo de consulta SQL BigQuery
Para comprobar que la información es correcta podemos usar la siguiente consulta:
SELECT prb_id, avg, min max
FROM `pablo-glez.altas_latency_mad_gcp_zone.belgium`
WHERE avg != -1.0
ORDER BY avg asc
LIMIT 1000Que dará como resultado:
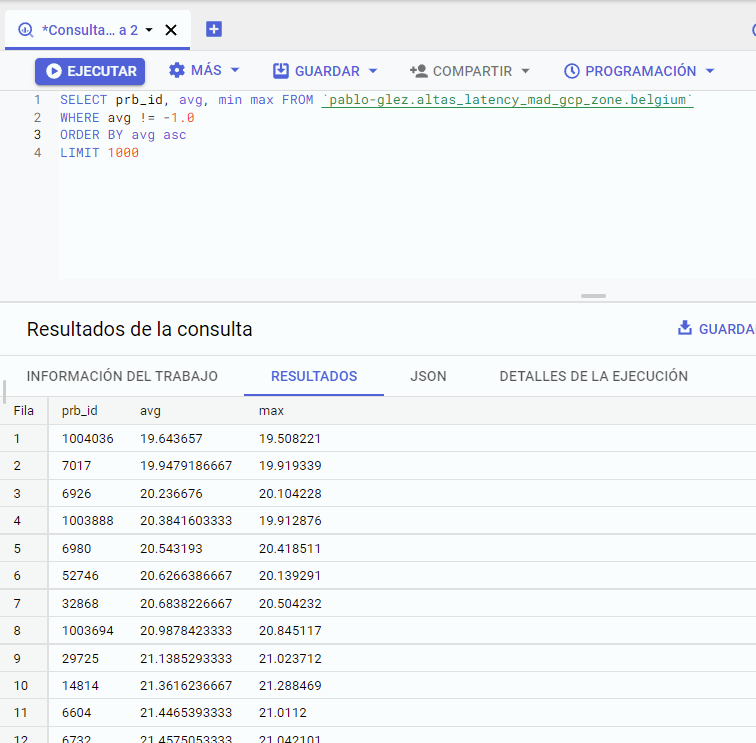
Datos sobre coordenadas geográficas
Inicialmente debemos obtener, desde los datos obtenidos desde RIPE Atlas, cuáles son las probes que han intervenido en la measurement.
gsutil cp gs://pablo-glez/ES-RIPE-Atlas-measurement-41688525.json .
cat ES-RIPE-Atlas-measurement-41688525.json | jq .prb_idEl comando de la línea 2 parseará el JSON para ofrecernos únicamente los IDs de las probes, una por línea.
Si únicamente queremos la los datos de una prueba podemos usar los siguientes comandos. El primero para obtener la longitud y el segundo para la latitud
curl -s https://atlas.ripe.net/api/v2/probes/715/ | jq .geometry.coordinates[0]
curl -s https://atlas.ripe.net/api/v2/probes/715/ | jq .geometry.coordinates[1]Sin embargo, queremos los datos de más de 150 probes. Inviable hacerlo de forma manual. ¿Qué hacemos entonces? Efectivamente, ¡automatizar el proceso!
Con este sencillo script:
#!/bin/bash
probe_id=${1}
temp=`curl -s https://atlas.ripe.net/api/v2/probes/${probe_id}`
latitude=`echo ${temp} | jq .geometry.coordinates[1]`
longitude=`echo ${temp} | jq .geometry.coordinates[0]`
echo "\"${probe_id}\",\"${latitude}\",\"${longitude}\"" >> data.csvA continuación, generamos el archivo `data.csv`, añadiendo también los nombres de las columnas:
echo "\"probe_id\",\"latitude\",\"longitude\"" >> data.csvEl script espera que pasemos mediante entrada estándar (STDIN) un ID de Probe cada vez. Por tanto, le llamaremos de la siguiente forma:
jq .prb_id ES-RIPE-Atlas-measurement-41688525.json | xargs -I % ./get-geo.sh %El resultado es sencillo, pero potente:
"probe_id","latitude","longitude"
"1000650","41.3775","2.0495"
"1000961","40.3775","-3.7695"
"1001462","43.3585","-2.8495"Unión de datos en una vista de BigQuery
Después de unir las fuentes de datos en BigQuery me di cuenta de que no era la solución más óptima, y me limitaba bastante a la hora de “jugar” con los datos. Por tanto, opté por la opción de unificar los datos en BigQuery en lugar de hacerlo en Data Studio.
La vista es generada con la siguiente consulta SQL (sí, con JOIN estaría mejor… ?):
SELECT
be.prb_id as prb_id,
es.avg as es_avg,
be.avg as be_avg,
(be.avg - es.avg) as diff,
CONCAT(geo.latitude,", ",geo.longitude) as geo_coords,
FROM
`pablo-glez.altas_latency_mad_gcp_zone.belgium` as be,
`pablo-glez.altas_latency_mad_gcp_zone.spain` as es,
`pablo-glez.altas_latency_mad_gcp_zone.geo-data` as geo
WHERE
be.prb_id = es.prb_id AND
be.prb_id = geo.probe_id AND
( be.avg != -1.0 OR es.avg != -1.0 )
ORDER BY es.avg asc