Spotify Stats con BigQuery y Data Studio - 1: Acceso a Datos
En este artículo veremos cómo obtener nuestro historial de reproducción de Spotify, para luego almacenarlo en Google BigQuery y visualizarlo con Google Data Studio.


En este artículo veremos cómo obtener nuestro historial de reproducción de Spotify, para luego almacenarlo en Google BigQuery y visualizarlo con Google Data Studio.
Abstract
Si una empresa domina a día de hoy el mercado de la reproducción de música es Spotify (fuente). Con un crecimiento exponencial, tanto en usuarios absolutos como en usuarios de pago.
Uno de esos usuarios es un servidor, que lleva usando Spotify desde hace años y es usuarios de pago desde hace más de un año, que coinciden con el crecimiento exponencial de las horas de reproducción.
¿Y qué ocurre cuando se juntan estadísticas, bases de datos, data visualization, e inquietudes informáticas? Nada sencillo, desde luego. Pero también puede surgir una gran idea y sobre todo, mucho aprendizaje.
En este documento se pretende recoger el proceso y el resultado de crear una panel de visualización de estadísticas de reproducción en dicha plataforma. Navegando por Internet es posible encontrar multitud de ejemplos, incluso utilizando la misma herramienta que utilizo en mi caso, Google Data Studio aunque con ciertos cambios en el tratamiento de los archivos.
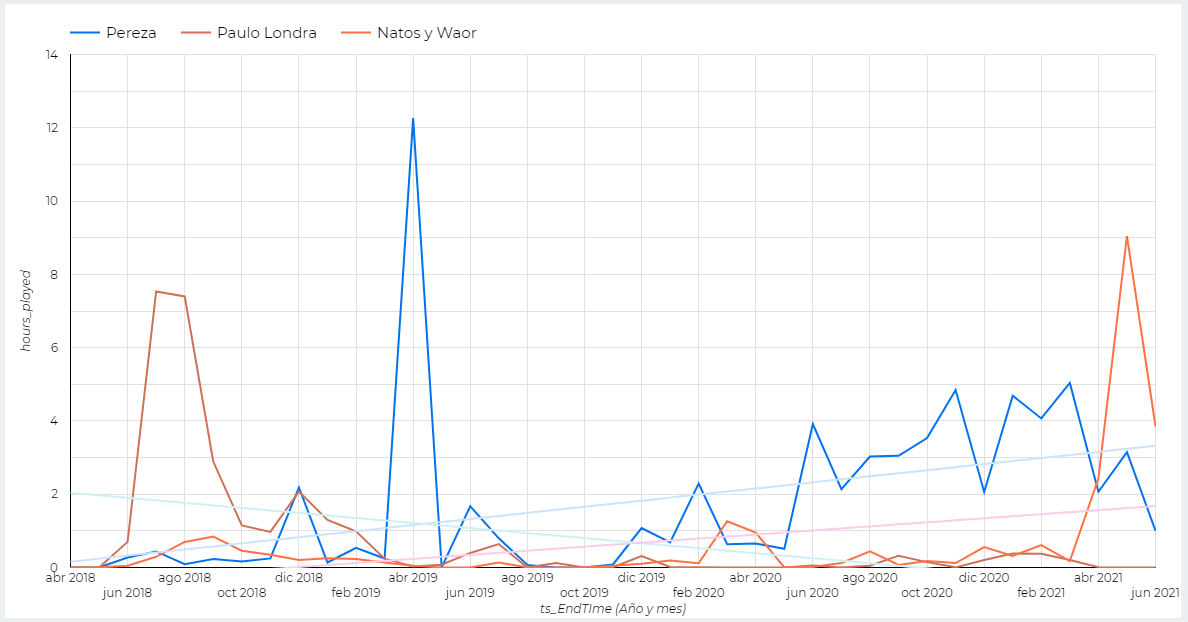
Aquí tenemos un ejemplo de la evolución de las horas escuchadas para tres artistas diferentes. No han sido elegidos al azar, sino de forma consciente para ver las líneas de tendencia.
Datos
Entre muchos otros detalles beneficiosos que la entrada en vigor del RGPD (Régimen General de Protección de Datos; GDPR en inglés) trajo consigo fue la garantización del acceso a los datos por parte de los usuarios.
¿Qué datos guarda Spotify? Pues realmente guarda muchísima información. Pero es realmente transparente en este sentido y es una empresa europea, por lo que a priori lo hace con garantías.
En esta página se puede obtener más información sobre la protección de datos en la Unión Europea, en esta página se encuentra la información concreta de Spotify en lo que se refiere a datos y privacidad.
Acceso a los datos
Para acceder a la información, lo primero que debemos tener es una cuenta de Spotify (esto se sobreentiende pues no es posible tener un historial de reproducción si no tenemos cuenta en la plataforma).
Según la cantidad de datos a los que queramos acceder tenemos dos vías. Por un lado, tenemos la vía “sencilla”. Esta es la opción recomendada para la mayoría de los usuarios, pues permite “jugar” con datos reales de forma sencilla. Mediante esta opción tenemos la posibilidad de descargar, entre otra información, nuestro historial de reproducción del último año. El detalle de la información contenida en esta solicitud se encuentra disponible en este enlace.
Podemos solicitar dicha información desde el apartado de privacidad de nuestra cuenta de Spotify, accesible a través de este enlace. Debemos seguir los pasos indicados en la parte inferior de la página, verificar por correo electrónico que deseamos los datos y en cuestión de unos días (3 en mi caso, pero legalmente la demora puede ser de hasta 30 días) recibiremos una notificación vía correo electrónico con un enlace para descargar un archivo en formato comprimido ZIP con nuestros datos (son divididos según la categoría en archivos JSON) y un magnífico PDF donde se explica cómo interpretar la información.
Si necesitamos información adicional, nuestras reproducciones del último año no son suficientes y/o queremos todo (todo, todo) el registro técnico que la empresa guarda sobre nosotros debemos contactar con el equipo de Soporte de Spotify utilizando este formulario o enviar un correo electrónico a la dirección [email protected]. Esta otra vía es algo más lenta, serán necesarias varias comunicaciones por parte nuestra y del equipo de Spotify. Recibiremos por un lado la información técnica detallada y días más tarde todo el historial de reproducciones de la cuenta (ordenado de forma extraña, aparentemente).
Esta segunda forma de acceder nos provee de quizá demasiada información, pero sin duda compensa símplemente por el hecho de conocer la magnitud de la recogida de datos.
También tenemos disponible la web de estadísticas a nivel global de Spotify que nos provee de tendencias de escucha muy interesantes. Aquí se muestra un ejemplo con el programa de visualización de datos Tableau y en este enlace se puede acceder a un informe realizado con dicho programa con la información de Spotify Charts.
Transformación de datos
Según accedamos a los datos utilizando una vía u otra, el esquema y la magnitud será distinta. En el caso de el primer método, con el historial de 1 año, un ejemplo de datos podría ser el siguiente (fragmento real ligeramente editado):
[
{
"endTime" : "2020-03-01 14:17",
"artistName" : "El Canto Del Loco",
"trackName" : "No Puedo Vivir Sin Ti",
"msPlayed" : 32004
},
{
"endTime" : "2020-03-02 19:36",
"artistName" : "Arcangel",
"trackName" : "Mi Primer Kilo",
"msPlayed" : 21152
},
{
"endTime" : "2020-03-03 12:54",
"artistName" : "Shawn Mendes",
"trackName" : "There's Nothing Holdin' Me Back",
"msPlayed" : 2586
},
{
"endTime" : "2020-03-04 06:28",
"artistName" : "Sia",
"trackName" : "Thunderclouds (feat. Sia, Diplo, and Labrinth)",
"msPlayed" : 187026
}
]Si accedemos a los datos utilizando el segundo método, los datos no están tan procesados, por lo que recibimos JSON (uno o más, dependiendo de cuánto hayamos utilizado el servicio). Una entrada de dicho archivo es así:
{"ts":"2018-09-07T06:28:05Z","username":"XXXXXXXXX","platform":"Android OS 8.1.0 API 27 (MARCA, MODELO)","ms_played":0,"conn_country":"ES", "ip_addr_decrypted":"XX.XX.XX.XX","user_agent_decrypted":"XXXX","master_metadata_track_name":"Perdóname","master_metadata_album_artist_name":"FMK","master_metadata_album_album_name":"Perdóname","spotify_track_uri":"spotify:track:4Uy3Q3h0VbWWyyiB1MmRoP","episode_name":null,"episode_show_name":null,"spotify_episode_uri":null,"reason_start":"clickrow","reason_end":"unexpected-exit-while-paused","shuffle":true,"skipped":null,"offline":false,"offline_timestamp":1536296766003,"incognito_mode":false}Nótese que se han reemplazado ciertos datos por equis. En mi caso, recibí 5 archivos endsong_0.json, endsong_1.json … endsong_4.json, con más de 70.000 registros (siendo aproximadamente la mitad del último año).
Si bien existen aplicaciones que permiten trabajar directamente con esta clase de archivos sin “trabajarlos” mucho, en mi caso han sido necesarias ciertas transformaciones.
Al ser archivos en formato JSON, trabajaremos bajo Linux (Ubuntu 18.04 en Windows Subsystem for Linux y Debian en Google Cloud Shell) con el comando jq, entre otros comandos consideramos de uso general.
Transformación de los datos - Método 1
Si los datos los hemos obtenido utilizando el método 1, tendremos X archivos del estilo StreamingHistoryX.json, siendo X un número incremental empezando por 0 la sucesión.
cat StreamingHistory0.json | jq -c '.[]' > StreamingHistory0_mod.json
cat StreamingHistory1.json | jq -c '.[]' > StreamingHistory1_mod.json
cat StreamingHistory2.json | jq -c '.[]' > StreamingHistory3_mod.jsonCon el comando anterior lo que hacemos es convertir cada registro en una línea, además, eliminamos los corchetes de inicio y cierre del JSON.
Realizamos el proceso archivo por archivo para poder detectar errores. En este caso no son archivos pesados (~1.5MB) pero puede sernos útil en ciertas ocasiones.
Veamos la entrada y la salida de este comando. De los datos arriba indicados como ejemplo obtenemos el siguiente resultado (sin los saltos de línea):
{"endTime":"2020-03-01 14:17","artistName":"El Canto Del Loco","trackName":"No Puedo Vivir Sin Ti","msPlayed":32004}
{"endTime":"2020-03-02 19:36","artistName":"Arcangel","trackName":"Mi Primer Kilo","msPlayed":21152}
{"endTime":"2020-03-03 12:54","artistName":"Shawn Mendes","trackName":"There's Nothing Holdin' Me Back","msPlayed":2586}
{"endTime":"2020-03-04 06:28","artistName":"Sia","trackName":"Thunderclouds (feat. Sia, Diplo, and Labrinth)","msPlayed":187026}Si bien es menos legible a primera vista, para cualquier software será sencillo reconocer cada entrada al existir un salto de línea separándolas. ¿Es un JSON correctamente formado? No al completo, pero para nuestro caso de uso es justo lo que necesitamos.
Por sencillez, es muy recomendable unir todos los archivos en uno, que será el que utilicemos posteriormente. ¿Cómo podemos unificar los archivos? ¡Con comandos de Linux!
# Con estos comandos estamos redirigiendo la salida del “cat” hacia el
# archivo StreamingHistory.json. En la segunda y siguientes
# ejecuciones, utilizamos el doble direccionador “>>” para anexar al
# final del archivo la salida, en caso de utilizar solo uno estaríamos
# sustituyéndolo.
cat StreamingHistory0_mod.json > StreamingHistory.json
cat StreamingHistory1_mod.json >> StreamingHistory.json
cat StreamingHistory2_mod.json >> StreamingHistory.json
# Otra opción:
cat StreamingHistory{0..2}_mod.json >> StreamingHistory.json
Una vez hayamos completado estos pasos tendremos un archivo único con todo nuestro historial del último año.
Transformación de datos - Método 2
Si hemos decidido que queremos obtener el historial completo de nuestra reproducción en Spotify, puede ser más complicado el proceso. No realmente por los comandos en sí, sino porque tenemos más registros (más tiempo de historial) y estos registros son más extensos al contener más datos. En mi caso, recibí 5 archivos JSON por parte de Spotify. 4 de 10MB (aprox) y un último de 5MB.
cat endsong_0.json | jq -c '.[]' > endsong_0_mod.json
cat endsong_1.json | jq -c '.[]' > endsong_1_mod.json
cat endsong_2.json | jq -c '.[]' > endsong_2_mod.json
cat endsong_3.json | jq -c '.[]' > endsong_3_mod.json
cat endsong_4.json | jq -c '.[]' > endsong_4_mod.json
# Otra opción
for i in {0..4}
do
cat endsong_${i}.json | jq -c '.[]' > endsong_${i}_mod.json
doneCon el comando anterior (al igual que hemos hecho anteriormente) lo que hacemos es convertir cada registro en una línea, además, eliminamos los corchetes de inicio y cierre del JSON.
Realizamos el proceso archivo por archivo para poder detectar errores. En este caso no son archivos pesados (~1.5MB) pero puede sernos útil en ciertas ocasiones.
Para terminar, y como hemos realizado con los datos al obtenerlos mediante el método 1, lo mejor es combinar los archivos en un único archivo conjunto. Esto nos permitirá flexibilidad y optimización a la hora de cargar los datos en BigQuery. Sí es cierto que en ciertos supuestos puede ser contraproducente tener un único archivo, si se van a producir lecturas simultáneas o aleatorias. De hecho, el archivo detallado (método 2) no está ordenado por fecha de reproducción.
cat endsong{0..4}_mod.json >> endsong_completo.jsonOtros comandos interesantes
Los comandos aquí citados son muy “low level”. Con esto se quiere indicar que no son comandos especializados para esta tarea, sino todo lo contrario. Conocer estos comandos nos va a permitir ser más eficientes en nuestro día a día.
No incluimos en este apartado los comandos cat ni jq al haber sido comentados anteriormente.
Se ha utilizado el comando head. Que permite mostrar la parte superior (entiéndase como superior la parte inicial de un archivo) de los documentos de texto (como JSON). Por defecto si solo indicamos head $archivo nos muestra las 10 primeras líneas de $archivo. En el caso del método 1 puede ser suficiente, pero en el método 2 no tenemos saltos de línea en el archivo, todos los datos forman parte de un stream de caracteres. Para modificar la cantidad de datos que ofrece como salida este comando debemos utilizar los modificadores -n X para indicar el número de líneas que se mostrarán, o -c X siendo X el número de bytes que se mostrarán.
Veamos un ejemplo del comando head:
pablo@cloudshell:~$ head -n 2 StreamingHistory1_mod.json
{"endTime":"2020-08-28 15:06","artistName":"Amaral","trackName":"El universo sobre mí","msPlayed":249704}
{"endTime":"2020-08-28 15:10","artistName":"Maldita Nerea","trackName":"Tu Mirada Me Hace Grande","msPlayed":257626}
pablo@cloudshell:~$ head -n 2 StreamingHistory0_mod.json
{"endTime":"2020-03-01 14:17","artistName":"El Canto Del Loco","trackName":"No Puedo Vivir Sin Ti","msPlayed":32004}
{"endTime":"2020-03-02 19:36","artistName":"Arcangel","trackName":"Mi Primer Kilo","msPlayed":21152}Si el comando head muestra la parte inicial de un archivo, el comando tail muestra las últimas líneas de un archivo. Junto con head, nos permitirá comprobar qué información contiene los archivos sin necesidad de abrirlos con un editor de texto (gráfico o no) ni imprimir por pantalla el contenido completo, con la consiguiente mejora de eficiencia.
Este comando funciona con los mismos modificadores de comandos que head. Utilizaremos -n X para indicar el número de líneas que se mostrarán, o -c X siendo X el número de bytes que se mostrarán.
pablo@cloudshell:~$ tail -n 2 StreamingHistory0_mod.json
{"endTime":"2020-08-28 14:59","artistName":"El Canto Del Loco","trackName":"Puede Ser (with Amaia Montero)","msPlayed":173482}
{"endTime":"2020-08-28 15:02","artistName":"Despistaos","trackName":"Física o química","msPlayed":190149}
pablo@cloudshell:~$ tail -c 300 StreamingHistory0_mod.json
56","artistName":"Pereza","trackName":"Animales","msPlayed":944}
{"endTime":"2020-08-28 14:59","artistName":"El Canto Del Loco","trackName":"Puede Ser (with Amaia Montero)","msPlayed":173482}
{"endTime":"2020-08-28 15:02","artistName":"Despistaos","trackName":"Física o química","msPlayed":190149}Uno de los problemas con los que nos podemos encontrar es que tenemos muchas información muy compacta y puede ser complicado ver de forma sencilla datos clave.
Para ese filtrado de información tenemos el comando grep. Al utilizar el comando destacamos partes de la salida de un comando. En el caso de los archivos obtenidos mediante el método 2 es relativamente importante pues no es posible ver de forma sencilla al ser un único stream de datos. Utilizando el siguiente comando se nos destacará en la salida cada vez que aparezca “ts” en color rojo. Se utiliza “ts” pues cada entrada va precedida por ese texto, que marca el timestamp del final de la reproducción.
A continuación, puedes leer el segundo artículo sobre este tema en el que trataré la carga de datos en BigQuery y visualizarlo en Google Data Studio:
¿Alguna duda?
No dudes en ponerte en contacto conmigo para cualquier duda, sugerencia, queja o aclaración que creas necesaria. ¡Será un placer hablar contigo!